Intro
I am a research manager at ByteDance. I received my Ph.D. in Computer Science and Engineering from The Ohio State University in 2017. I worked with Professor DeLiang Wang in Perception and Neurodynamics Laboratory. My PhD research focused on data-driven speech separation in adverse environments. I am currently interested in music understanding/generation, music creation tools, and multimodal foundation models.
Work
- 2018/09 ~ present: Research Manager, Audio/Speech/Music Understanding and Generation, ByteDance, San Jose, CA
- 2017/06 ~ 2018/08: Research Scientist, Speech Recognition and Speech Synthesis, Baidu Research, Sunnyvale, CA
- 2016/05 ~ 2016/08: Research Intern, Speech and Language Algorithms, Google Research, New York, NY
- 2015/05 ~ 2015/08: Data Science Intern, Natural Language Processing, MetaMind, Palo Alto, CA
Publications
- Siyuan Shan, Lamtharn Hantrakul, Jitong Chen, Matt Avent and David Trevelyan: Differentiable Wavetable Synthesis. ICASSP, 2022.
- Wei Ping, Kainan Peng, Jitong Chen: ClariNet: Parallel Wave Generation in End-to-End Text-to-Speech. [audio demos], ICLR, 2019.
- Sercan O. Arik, Jitong Chen, Kainan Peng, Wei Ping, and Yanqi Zhou: Neural Voice Cloning with a Few Samples. [audio demos], NIPS, 2018.
- DeLiang Wang and Jitong Chen: Supervised Speech Separation Based on Deep Learning: An Overview. IEEE/ACM Transactions on Audio, Speech, and Language Processing, 2018.
- Jitong Chen and DeLiang Wang: DNN Based Mask Estimation for Supervised Speech Separation. In: Shoji Makino (ed.), Audio Source Separation, Springer, 2018.
- Ke Tan, Jitong Chen, and DeLiang Wang: Gated Residual Networks with Dilated Convolutions for Monaural Speech Enhancement. IEEE/ACM Transactions on Audio, Speech, and Language Processing, 2018.
- Ke Tan, Jitong Chen, and DeLiang Wang: Gated Residual Networks with Dilated Convolutions for Supervised Speech Separation. ICASSP, 2018.
- Eric Battenberg, Jitong Chen, Rewon Child, Adam Coates, et al.: Exploring Neural Transducers for End-to-End Speech Recognition. ASRU, 2017.
- Jitong Chen: On Generalization of Supervised Speech Separation. Ph.D. Dissertation, The Ohio State University, 2017.
- Jitong Chen and DeLiang Wang: Long Short-Term Memory for Speaker Generalization in Supervised Speech Separation. Journal of the Acoustical Society of America, 2017.
- Jitong Chen and DeLiang Wang: Long Short-Term Memory for Speaker Generalization in Supervised Speech Separation. INTERSPEECH, 2016.
- Jitong Chen, Yuxuan Wang, Sarah Yoho, DeLiang Wang and Eric Healy: Large-Scale Training to Increase Speech Intelligibility for Hearing-Impaired Listeners in Novel Noises. Journal of the Acoustical Society of America, 2016.
- Jitong Chen, Yuxuan Wang, and DeLiang Wang: Noise Perturbation for Supervised Speech Separation. Speech Communication, 2016.
- Eric Healy, Sarah Yoho, Jitong Chen, Yuxuan Wang, and DeLiang Wang: An Algorithm to Increase Speech Intelligibility for Hearing-Impaired Listeners in Novel Segments of the Same Noise Type. Journal of the Acoustical Society of America, 2015.
- Jitong Chen, Yuxuan Wang, and DeLiang Wang: Noise Perturbation Improves Supervised Speech Separation. LVA/ICA, 2015.
- Jitong Chen, Yuxuan Wang, and DeLiang Wang: A Feature Study for Classification-Based Speech Separation at Low Signal-to-Noise Ratios. IEEE/ACM Transactions on Audio, Speech, and Language Processing, 2014.
- Jitong Chen, Yuxuan Wang, and DeLiang Wang: A Feature Study for Classification-Based Speech Separation at Very Low Signal-to-Noise Ratio. ICASSP, 2014.
- Jerome Vienne, Jitong Chen, Md. Wasi-Ur-Rahman, Nusrat S. Islam, Hari Subramoni, Dhabaleswar K. Panda: Performance Analysis and Evaluation of InfiniBand FDR and 40GigE RoCE on HPC and Cloud Computing Systems. HOTI, 2012.
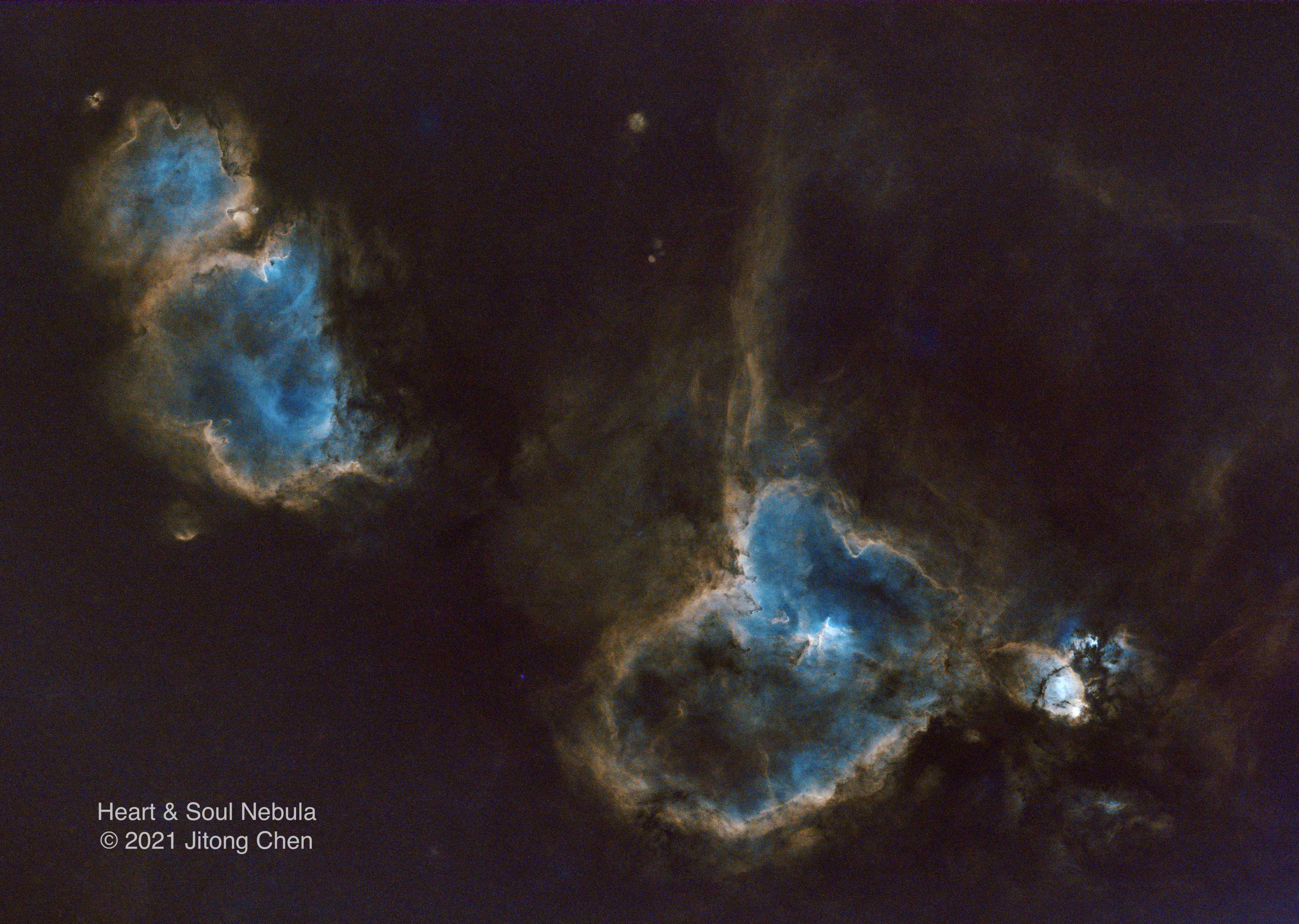
Astrophotography
I am intersted in astrophotography. I am always amazed by the wonder of our universe.

Orion Nenbula, RGB

Horsehead Nebula, SHO

Whirlpool Galaxy, RGB

Rossette Nebula, SHO